Table of Contents
- PISF Risk Management Framework: Risk Appetite & Tolerance Guide — The Operational Gap to Fix Now
- What Risk Appetite and Risk Tolerance Mean for PISF—and Why the SOC Must Own the Operational Side
- How Cyber Silos Form in Modern Environments — and Why They Break Risk Management PISF
- Why Fragmented Security Tooling Fails at Scale
- SIEM as the Enforcement Point for Risk Management PISF
- Log Ingestion and Normalization — The Foundation of Reliable Tolerances
- Cross-Domain Correlation and Rule Design for Operational Tolerances
- Real-Time Analytics and Baselining
- Automation and Orchestration to Reduce MTTD and MTTR
- Operationalizing Risk Appetite With SIEM-Driven Controls and Metrics
- Risk Register and Control Mapping: Linking Telemetry to Controls
- Compliance Monitoring and Auditability Under PISF
- The Cost of Delayed Detection and Response — A Numerical Perspective
- Scaling SIEM for Hybrid and Cloud Environments Under PISF
- Hypothetical Scenario: Putting It Into Practice
- Checklist: Align PISF Risk Appetite With SIEM-Driven Tolerances
- Governance, Roles and Continuous Improvement
- Why Threat Hawk SIEM From CyberSilo Is the Practical Choice for Enforcing PISF Risk Management
- Next Steps: Operational Readiness and Measurement
- Conclusion: Link Appetite to Action or Accept Continued Exposure

PISF Risk Management Framework: Risk Appetite & Tolerance Guide — The Operational Gap to Fix Now
Operational leaders implementing risk management PISF face a single hard problem: translating board-level risk appetite into measurable, enforceable tolerances that SOCs can monitor and act upon in real time. Without a usable bridge between strategy and telemetry, risk acceptance becomes a paper exercise and compliance monitoring turns into noise. This guide shows how to map risk appetite into SIEM-driven tolerances, close cyber silos that invalidate PISF controls, and operationalize continuous risk management so SOC teams measurably reduce exposure, MTTD and MTTR.
What Risk Appetite and Risk Tolerance Mean for PISF—and Why the SOC Must Own the Operational Side
Risk appetite in the context of PISF defines the level of cyber risk an organisation is willing to accept in pursuit of its objectives. Risk tolerance converts that appetite into operational thresholds—specific statements about how much deviation, exposure or residual risk is acceptable for identified assets, processes or data classes. Translating appetite into tolerance requires measurable indicators that are continuously observable by the SOC.
For enterprise security leaders this creates three immediate requirements:
- Define measurable indicators (MTTD windows, acceptable incident volumes, allowed vulnerability age, acceptable lateral movement risk, etc.).
- Instrument those indicators in a centralized monitoring layer (SIEM) so tolerances become live alerts and dashboards, not policy text.
- Assign operational ownership and escalation so tolerances trigger accepted responses—remediation, mitigation, risk acceptance or transfer—within defined SLAs.
Risk Appetite vs. Risk Tolerance: Clear Operational Definitions
Risk appetite: Strategic statement such as "We will accept residual risk up to X for non-production systems to enable rapid innovation."
Risk tolerance: Quantified, operational thresholds such as "No more than 5 high-severity unmitigated vulnerabilities older than 30 days on critical production assets" or "Average MTTD for high-confidence endpoint detections must be ≤ 4 hours."
How to Convert Strategic Appetite Into SOC-Ready Tolerances
- Start with business objectives and map assets that enable those objectives.
- For each asset class, define acceptable failure modes and quantify them (downtime, data exposure in MB, time-to-detect).
- Identify the SIEM signals and telemetry needed to observe those failure modes.
- Define escalation actions tied to each threshold (automated containment, patch tickets, executive notification).
- Implement continuous testing and review cycles to validate that tolerances remain relevant as threat landscape or business priorities change.
Transform Your Risk Management Strategy
Discover how CyberSilo's Threat Hawk SIEM can help you operationalize your risk appetite and enforce measurable tolerances. Our experts will guide you through mapping strategic objectives to actionable SOC controls.
How Cyber Silos Form in Modern Environments — and Why They Break Risk Management PISF
Cyber silos form when tooling, telemetry and ownership are split by domain—network, endpoint, identity, cloud, applications—without a central correlation and governance layer. Common root causes:
- Procurement driven by departmental needs rather than enterprise-wide visibility.
- Separate logging stacks and retention policies for cloud and on-prem systems.
- Incompatible schemas and identity models across tooling.
- Operational turf—teams keep their alerting and hand-offs ad hoc rather than integrated into a single incident workflow.
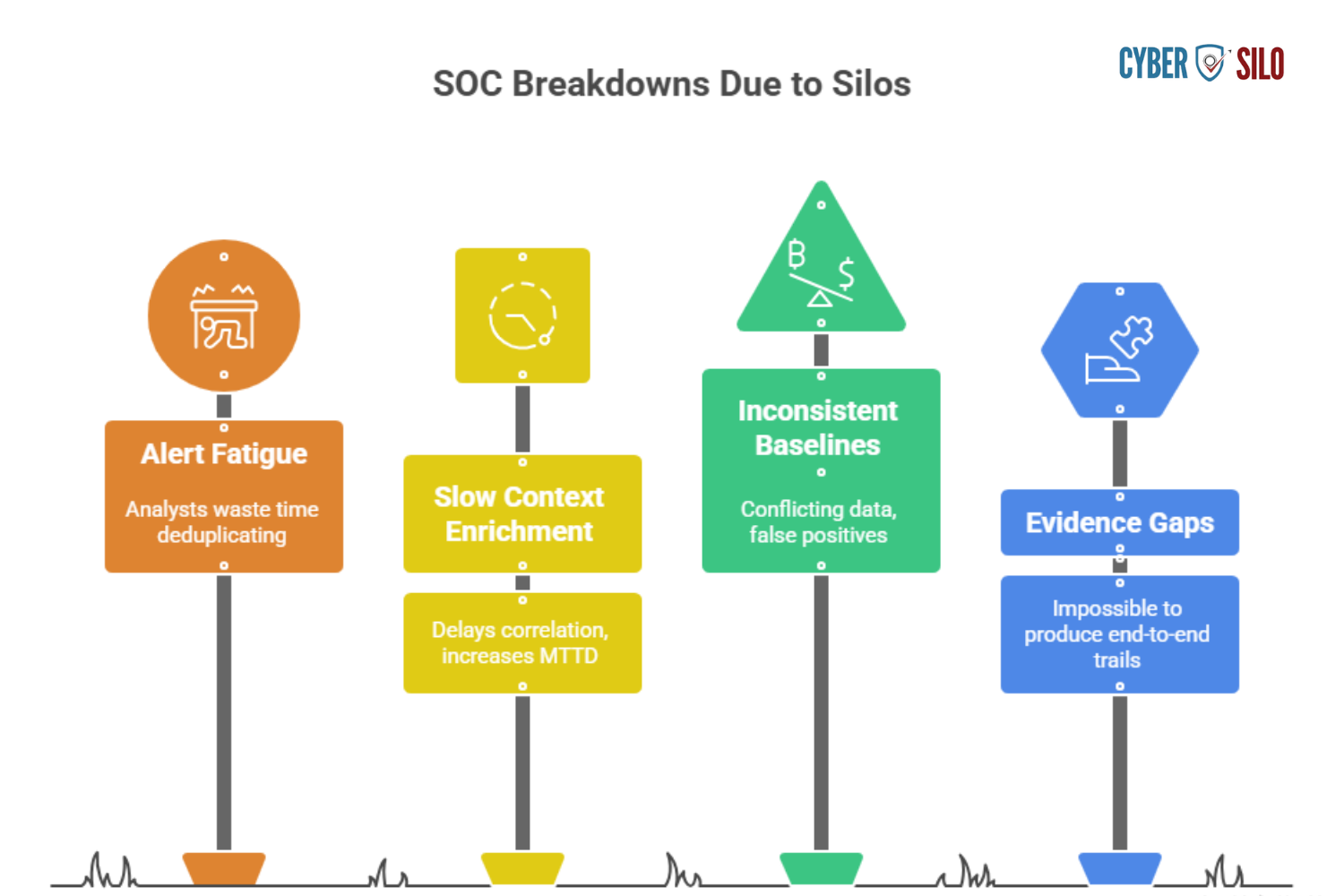
The operational consequences for PISF are predictable: blind spots that invalidate risk assumptions, duplicated efforts that increase alert fatigue, and fragmented incident evidence that undermines audits and compliance monitoring.
Real SOC-Level Breakdowns Caused by Silos
- Alert fatigue: multiple tools create duplicated alerts with different severities; analysts spend cycles deduplicating rather than investigating.
- Slow context enrichment: identity logs in a separate system delay correlation with endpoint telemetry, increasing MTTD.
- Inconsistent baselining: different datasets produce conflicting baselines for normal activity, leading to either false positives or missed detections.
- Evidence gaps for audits: compliance reviews require end-to-end trails that are impossible to produce when logs live in silos.
Why Fragmented Security Tooling Fails at Scale
A fragmented stack can work for pilots. It fails at enterprise scale because it multiplies complexity: log schemas diverge, retention costs spike, and operations must stitch data together manually. The economic and risk impacts manifest as:
- Higher operational costs from fragmented storage and duplicated tooling.
- Longer incident timelines due to manual enrichment and context switching.
- Inaccurate risk reporting—C-level dashboards become unreliable when derived from partial data.
- Diluted control effectiveness—controls are verified in silos but not correlated across attack paths.
SIEM as the Enforcement Point for Risk Management PISF
The SIEM is the only practical enforcement point that can translate risk appetite into continuous observability. A well-designed SIEM performs three critical functions:
- Centralized log aggregation and normalization so signals are comparable and correlation is possible across domains.
- Real-time correlation and analytics that map patterns against tolerance thresholds (e.g., anomalous privilege escalation across identity and endpoint telemetry translates to elevated risk posture for targeted assets).
- Operational orchestration that turns tolerance breaches into measured remediation: automated containment, ticketing, and risk acceptance workflows.
Threat Hawk SIEM embodies these capabilities: engineered for elimination of cyber silos, centralized visibility across hybrid estates, real-time log correlation for accurate threat detection, and operational features that materially reduce MTTD and MTTR while improving compliance readiness at scale. To understand how Threat Hawk compares with other leading platforms, explore our comprehensive guide on the top 10 SIEM tools.
Threat Hawk SIEM Capabilities That Enforce PISF Tolerances
- Unified ingestion pipelines for network, endpoint, identity, cloud and application telemetry with a common schema.
- Cross-domain correlation engine that evaluates chained events and assigns contextual risk scores to assets and business units.
- Anomaly detection and ML-driven baselining tuned for enterprise behaviours to reduce false positives and alert fatigue.
- SOAR integration and native orchestration for automated remediation and escalation workflows tied to tolerance thresholds.
- Compliance-ready reporting templates and immutable audit trails for PISF reviews and regulatory audits.
Log Ingestion and Normalization — The Foundation of Reliable Tolerances
Operationalizing tolerance depends on fidelity of telemetry. Poor ingestion and inconsistent normalization create measurement error that invalidates tolerances. At the technical level this means:
- Parsing raw events into a canonical schema: timestamp, source, user, asset identifier, action, outcome, geo, and context fields such as process hash or cloud resource id.
- Enriching events with asset and business context: business unit, criticality, owner, and business impact score. Without enrichment, alerts can't be scoped against tolerance targets.
- Normalizing identity contexts across identity providers and federated services so you can tie authentication anomalies to the same entity across environments.
Practical Recommendations for Ingestion Pipelines
- Collect at source with lightweight forwarders and cloud-native ingestion to preserve fidelity and guarantee timestamps.
- Use schema mappings and reusable parsers to avoid manual rule rewrites when vendors or cloud services change log formats.
- Implement field-level normalization and store raw payloads to enable retrospective correlation and forensic analysis.
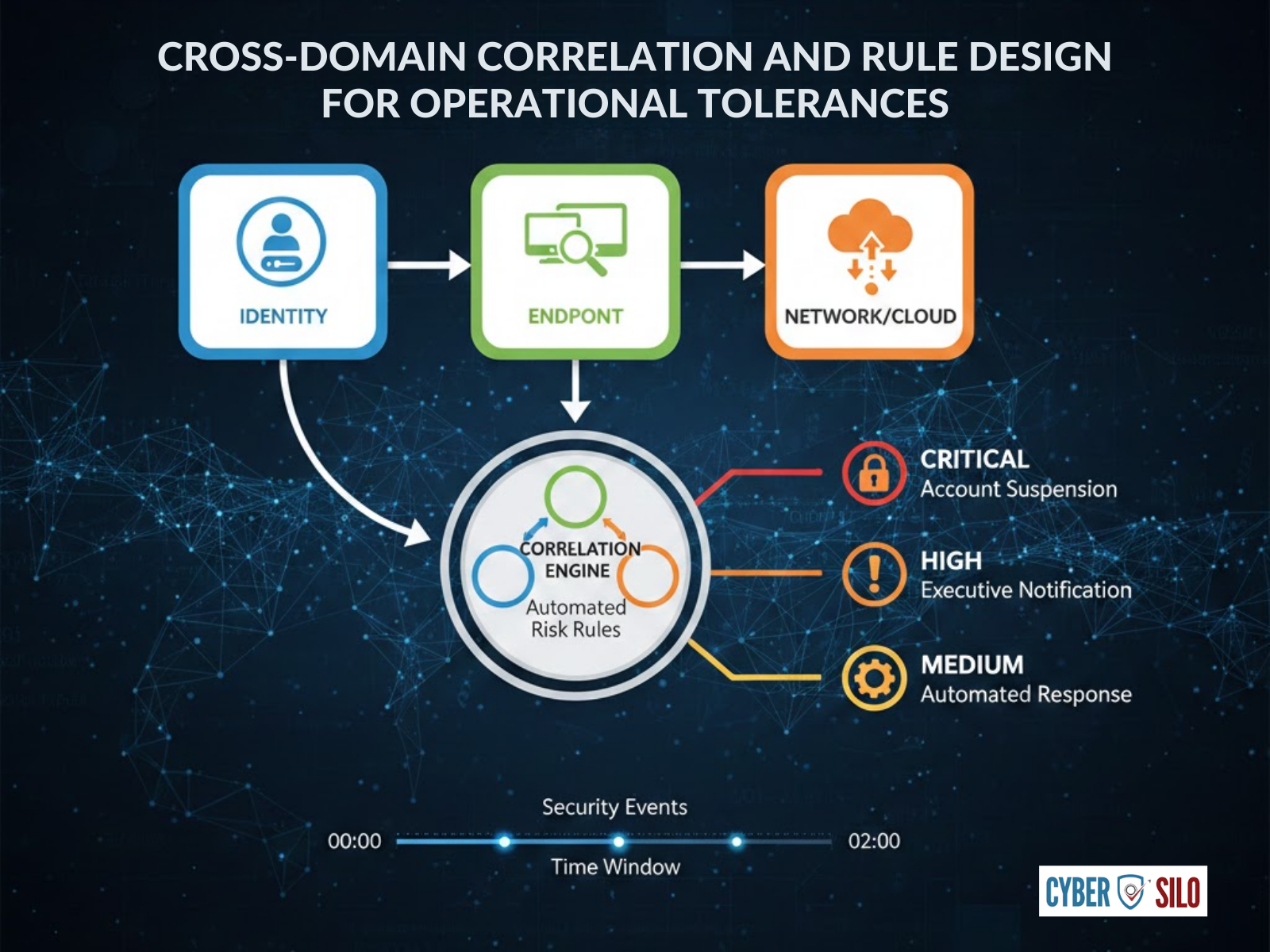
Cross-Domain Correlation and Rule Design for Operational Tolerances
Correlation rules implement tolerance logic. Rather than simple signature matches, rules should combine telemetry from multiple domains to create high-confidence conditions that reflect actual risk, not noise. Examples:
- Rule: "Unusual administrative logins (identity) + new process creation by that admin (endpoint) + abnormal data egress (network) within 2 hours" → Severity: Critical; Action: automated session termination, immediate containment, executive alert.
- Rule: "More than 3 failed MFA attempts (identity) followed by successful authentication from a new country (cloud) for an account with recent privilege escalation" → Severity: High; Action: require re-authentication, suspend access pending investigation.
Design rules to reflect tolerances—for example, if the business tolerance allows one-day windows for low-risk vulnerabilities but not for high-risk ones, rules should escalate automatically when age crosses tolerance thresholds.
Real-Time Analytics and Baselining
Baselining is essential to distinguish normal variability from true anomalies. Static thresholds produce noise in complex environments. Real-time analytics should:
- Establish dynamic baselines per asset class and business unit, accounting for seasonal or operational patterns.
- Use statistical deviation, rate-based detection and behavioural models to flag outliers that meaningfully exceed tolerances.
- Produce confidence scores so SOC analysts can prioritize high-impact events and avoid alert fatigue.
Automation and Orchestration to Reduce MTTD and MTTR
Once tolerances are instrumented and high-confidence detections are in place, automation closes the loop. Orchestration is not just ticket creation; it's a series of automated, auditable actions aligned to tolerance thresholds:
- Immediate containment: isolate endpoints, revoke sessions or block IPs automatically when thresholds indicate active compromise.
- Enrichment and decisioning: run asset and identity lookups, attach risk scores, and execute playbooks that either remediate, escalate, or mark for acceptance.
- Remediation workflows: open patch tickets, trigger configuration changes, or initiate forensic snapshots depending on tolerance and impact.
Automation reduces human latency and enforces consistent responses that align with PISF-defined tolerances, thereby lowering MTTR and limiting business impact.
Accelerate Your Incident Response
Learn how automation and orchestration can dramatically reduce your MTTD and MTTR. CyberSilo's proven playbooks and integration frameworks ensure your tolerances translate into immediate, effective action.
Operationalizing Risk Appetite With SIEM-Driven Controls and Metrics
To turn appetite into action you must define the operational metrics that measure adherence. These metrics should be visible in SOC dashboards and tied to both technical and business owners.
Core Metrics to Track
- Mean Time to Detect (MTTD) for high-confidence incidents (target defined by risk tolerance).
- Mean Time to Respond (MTTR) for containment and remediation actions.
- Percent of critical assets compliant with vulnerability tolerance (e.g., <30-day remediation for CVSS ≥ 9).
- False positive rate and analyst time per investigation to measure alert fatigue.
- Coverage percentage of telemetry for critical asset classes (endpoint, identity, cloud).
Designing Tolerance Thresholds in the SIEM
Translate tolerances into SIEM artifacts:
- Detections mapped to severity and confidence levels informed by tolerance definitions.
- SLA-driven playbooks that escalate alerts not resolved within tolerance windows.
- Dashboards that surface tolerance breaches by asset, business unit and control owner.
Every tolerance breach should create a traceable record: time breached, who was notified, actions taken, and final disposition. This is essential for PISF audits and for continuous improvement.

Risk Register and Control Mapping: Linking Telemetry to Controls
A usable risk register for PISF contains:
- Risk ID and description (tied to business objective).
- Risk appetite statement and tolerance thresholds (quantified).
- Controls in place and SIEM signal(s) that provide evidence for those controls.
- Control owners and remediation SLAs.
- Maturity level and planned improvements.
Map each control to specific SIEM detections and evidence sources. For example, a control for privileged access management should map to detections for privilege escalation, administrative logins from unusual locations, and session duration anomalies, with logs sourced from identity provider, endpoint and cloud access logs.
Compliance Monitoring and Auditability Under PISF
Regulators and internal auditors require reproducible evidence that tolerances were monitored and enforced. SIEM supports compliance by:
- Generating immutable audit trails for every tolerance breach and remediation action.
- Providing pre-built reporting aligned to common regulatory frameworks and PISF expectations.
- Maintaining retention and chain-of-custody for forensic evidence needed in investigations.
The Cost of Delayed Detection and Response — A Numerical Perspective
Quantifying the cost of delayed detection helps set realistic tolerances. Use the following practical model to estimate incremental loss from detection lag:
Estimated Loss = (Daily Business Impact × Exposure Days) + Containment Cost + Regulatory/Remediation Costs
Example: A compromised database containing regulated customer data.
- Daily Business Impact (lost revenue, customer churn, operational downtime): $50,000
- Exposure Days if MTTD = 10 days: 10
- Containment and forensic cost: $150,000
- Regulatory fines and customer notification cost: $300,000
Estimated Loss = ($50,000 × 10) + $150,000 + $300,000 = $950,000
If a SIEM-driven tolerance reduces MTTD from 10 to 2 days, the loss becomes ($50,000 × 2) + $150,000 + $300,000 = $600,000 — a 37% reduction. This simple model shows how operationalizing risk appetite and reducing detection horizons directly reduces financial exposure.
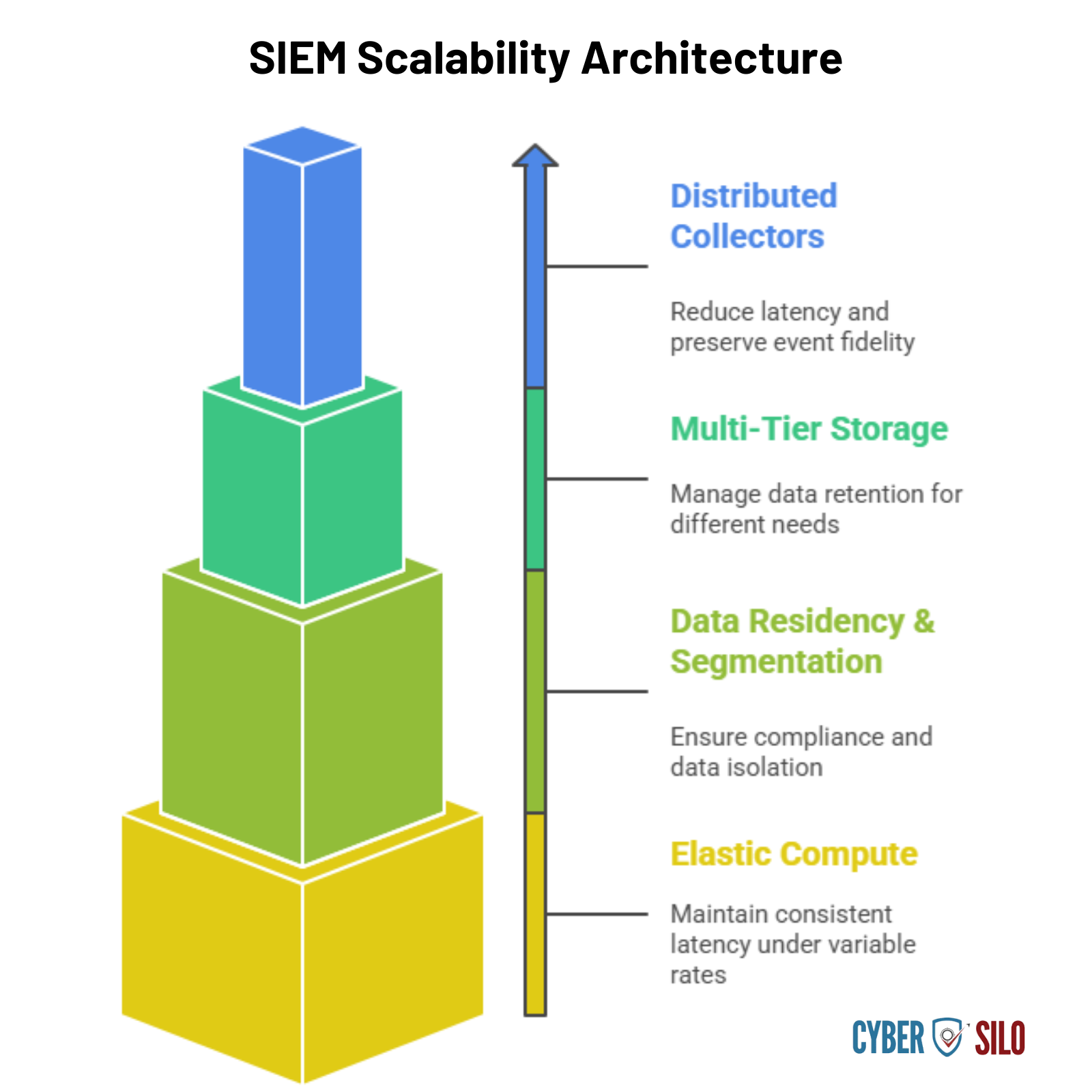
Scaling SIEM for Hybrid and Cloud Environments Under PISF
PISF requires scalability across on-prem, hybrid and cloud estates. Architectural considerations:
- Distributed collectors with centralized correlation: reduce latency and preserve event fidelity.
- Multi-tier storage: hot (recent events for analytics), warm (mid-term for investigations), cold (long-term retention for compliance).
- Data residency controls and multi-tenant segmentation for subsidiaries or regulated lines of business.
- Elastic compute for analytics so correlation latency remains consistent under variable ingestion rates.
Performance and Storage Considerations
Indexing strategy matters: index fields used in correlation and queries; compress raw payloads and keep them accessible for forensic tasks. Retention policies should align with PISF and regulatory requirements while balancing cost using tiered storage.
Hypothetical Scenario: Putting It Into Practice
Company X operates under PISF and sets a risk appetite that permits acceptable residual risk for non-customer-facing dev environments but zero tolerance for data-exfiltration on production systems. Steps to operationalize:
- Inventory and classify assets; mark production databases as "Tier 0".
- Define tolerances: any anomalous data egress from Tier 0 must be detected within 1 hour (MTTD ≤ 1 hour); any confirmed exfiltration must be contained within 3 hours (MTTR ≤ 3 hours).
- Implement Threat Hawk SIEM ingestion for database audit logs, network flows, cloud storage logs and DLP signals.
- Create correlated detection rules: combine increased outbound data flow, unusual authentication, and creation of new cloud storage objects to generate a critical incident with automatic containment (revoke credentials, block egress) and SOC notification.
- Measure outcomes: within 90 days, MTTD for Tier 0 anomalies falls from 12 hours to 40 minutes and MTTR falls from 36 hours to 4 hours. The improvement aligns with tolerance and materially reduces exposure.
Checklist: Align PISF Risk Appetite With SIEM-Driven Tolerances
- Document strategic risk appetite and map to asset classes.
- Define quantifiable tolerances for each asset class (time-based, volume-based, frequency-based).
- Inventory telemetry sources and ensure coverage for each tolerance metric.
- Normalize ingestion and enrich events with business context.
- Create cross-domain correlation rules that represent tolerance breaches.
- Integrate orchestration playbooks to enforce responses within tolerances.
- Expose tolerance KPIs on SOC dashboards and tie to SLA-driven alerts.
- Maintain a risk register mapping controls, SIEM evidence and owners.
- Automate audit evidence capture and retain logs according to PISF requirements.
- Review tolerances quarterly or after material changes in business priorities or threat landscape.
Start Your PISF Compliance Journey
Ready to operationalize your risk appetite with measurable, enforceable tolerances? Partner with CyberSilo to implement a comprehensive SIEM solution that aligns with PISF requirements and delivers tangible risk reduction.
Governance, Roles and Continuous Improvement
Operationalizing PISF tolerances requires clear governance:
- Board-level approval for risk appetite statements with delegated authority to a Risk Committee for tolerance changes.
- Security Operations ownership for monitoring, detection and initial response.
- Service owners for remediation actions and evidence provision.
- Periodic reviews to validate that tolerances remain aligned with business objectives and current threat landscape.
Continuous improvement should be data-driven: use SIEM metrics to identify chronic tolerance breaches, root cause the contributing failures (telemetry gaps, process breakdowns, inadequate controls), and close the loop with targeted remediation projects.
Why Threat Hawk SIEM From CyberSilo Is the Practical Choice for Enforcing PISF Risk Management
Threat Hawk SIEM is architected for the operational realities of PISF compliance and enterprise security programs. It eliminates cyber silos by providing unified log aggregation across hybrid estates, real-time correlation tuned for low false-positive detection, and orchestration that enforces tolerances with auditable actions. For SOC teams this yields:
- Reduced MTTD through correlated, confidence-scored detections.
- Lower MTTR via integrated automation and orchestration aligned to tolerance definitions.
- Less alert fatigue because detections are contextual and severity is tied to business impact.
- Faster audit readiness with immutable trails and compliance reporting templates tailored to PISF requirements.
Next Steps: Operational Readiness and Measurement
Setting tolerances is the start; proving them requires observability, enforcement and measurement. Begin with a targeted Risk Assessment Service engagement that maps current telemetry and controls to PISF tolerance needs, identifies gaps in log coverage, and defines a prioritized roadmap to instrument tolerances in Threat Hawk SIEM.
CyberSilo's assessment approach focuses on operational outcomes: reduce MTTD and MTTR, eliminate evidence gaps for audits, and configure SIEM playbooks that enforce tolerances without increasing analyst workload. The engagement produces a practical implementation plan with measurable success criteria tied to business risk reduction.
Conclusion: Link Appetite to Action or Accept Continued Exposure
A documented risk appetite is necessary but not sufficient for PISF. Without granular, measurable tolerances and a SIEM-enabled enforcement layer, risk remains unmonitored and the SOC operates in reactive mode. By eliminating cyber silos, normalizing telemetry, and mapping tolerance thresholds to automated detections and playbooks, organisations can turn strategic appetite into operational control. Threat Hawk SIEM provides the technical foundation to do this at enterprise scale: centralized visibility, real-time correlation, orchestration and compliance reporting. To move from policy to measurable risk reduction, schedule a Risk Assessment Service to baseline your current state, identify telemetry and control gaps, and begin enforcing PISF tolerances that materially lower exposure and improve SOC efficiency.
Take the first step towards operationalizing your risk management strategy. Contact our security team today to discover how CyberSilo can help you transform risk appetite into measurable, enforceable tolerances that protect your organization while enabling business objectives.